| Новости Энциклопедия переводчика Блоги Авторский дневник Форум Работа Декларация Поиск О нас пишут Награды Читальня Конкурсы Опросы | ||
Навигация
- Произошла ошибка при получении следующей новостной ленты: http://feeds.feedburner.com/trworkshop-blogs
![]()
- Произошла ошибка при получении следующей новостной ленты: http://feeds.feedburner.com/trworkshop-job
![]()
![]()
![]()
Содержание
Принципы подготовки текста к переводу
- Автор: mikhailo <mikhailo@tut.by>
- Лицензия: CC BY-NC-SA 3.0
Проблемы вёрстки текста, оказывающие влияние на перевод с использованием программ автоматизированного перевода (CAT)
После посещения 1-го Белорусского форума переводчиков, выступления с небольшим докладом и развернувшейся затем небольшой дискуссии я увидел, что многие переводчики, как бы даже владеющие навыками работы в CAT, приняли моё указание на то, что выпускники лингвистического, да и других вузов тоже, должны владеть навыками вёрстки текста в одном из основных своих рабочих инструментов (Microsoft Word (MS Word) или OpenOffice/LibreOffice Writer (LO Writer)), то ли с некоторым пренебрежением, то ли вообще в штыки (ну не царское это дело — вёрстка). Я понимаю, что часть переводчиков, постоянно работающая с присылаемыми готовыми пакетами в CAT, может даже никогда и не задуматься об этой проблеме. Однако понимание сути проблем, вызываемых вёрсткой в переводе, помимо повышения производительности, позволит начинающим переводчикам избежать проблем, стоящих массы нервных клеток, когда после экспорта перевода за 5 минут до сдачи вместо красивого документа открывается неприглядно выглядящая мешанина текста и картинок…
Такое понимание будет полезно и всем работающим с MS Word/LO Writer, чтобы просто уметь создавать нормальные документы, экономя при этом собственное время и нервы.
Поэтому, и по вежливой заинтересованности одного из преподавателей МГЛУ, я и решился написать данную статью.
В общем, проблемы, вызываемые вёрсткой в переводе, условно (из-за их тесного переплетения) можно разбить на три группы:
- Проблемы сегментации, или разбивки текста на единицы перевода. В самом крайнем случае, свойственном, правда, не MS Word или LO Writer, а САПР, адекватный перевод может стать невозможен или затраты времени на него выйдут за разумные пределы.
- Проблемы вёрстки, затрудняющие работу в CAT и снижающие её эффективность и производительность труда.
- Проблемы вёрстки, приводящие к искажению внешнего вида готового перевода вплоть до состояния, в котором ни один заказчик его не примет.
А теперь подробнее рассмотрим каждый клубок проблем. В качестве примера я буду приводить картинки из CAT DejaVuX. В Trados, MemoQ и других CAT они будут похожи.
Проблемы сегментации
Среди проблем сегментации, или разбивки текста на единицы перевода, можно условно выделить следующие:
- Разбивка предложений абзацами.
- Неразбивка предложений из-за отсутствия пробелов после конечного знака препинания, широкого использования имён собственных, начинающихся с маленькой буквы, в начале предложения (например, Kilgray с их MemoQ).
- Использование сокращений, отсутствующих в стандартных списках сокращений.
- Различная обработка табуляции в разных CAT на стандартных настройках (Trados и DejaVuX не разбивают сегменты по табуляции, MemoQ — разбивает).
- Перестановка сегментов (обычно в САПР).
- Разбивка предложений мелкими картинками в тексте (обычно в руководствах к ПО).
Разбивка предложений абзацами. Неразбивка соседних предложений
С этой проблемой, в разной мере, сталкивались абсолютно все переводчики. Выглядит она так:



И вот так в CAT:



В ситуации «полный ах», с которой в CAT без оригинала не справится даже самый опытный переводчик, она выглядит так:
| Оригинал | Текст в CAT. Обратите внимание на нарушение логического порядка следования сегментов |
|---|---|
 | 1) Film coefficients and fouling resistance are related to inside |
| Mapped Version 0, 07/21/00 | |
| the tubes. | |
| tube for air side. | |
| 2) Overall coefficients are related to the bare outer diameter of | |
| surfaces of tube for product side and bare outside surface of | |
| Air side |
Такую серьёзность проблема чаще всего имеет при переводе текста из САПР и DTP, если верстальщик неопытный. Применительно к ACAD в моей классификации она называется «TEXT-MTEXT-проблема» (TEXT в ACAD обозначает однострочный текст, MTEXT — многострочный). Когда единица перевода в САПР набирается в несколько отдельных строк (TEXT), которые при автоматическом импорте могут разделиться ещё несколькими строками из других частей чертежа, адекватный перевод без оригинала будет практически НЕВОЗМОЖЕН. А вот вытребовать оригинал у заказчика порой чрезвычайно тяжело. Поэтому, если жизнь столкнёт вас с возможностью повлиять на определение технических требований к предоставлению документации заказчиком — помните об этом. Если вы будете/станете менеджерами в бюро переводов (БП) — ВСЕГДА требуйте у заказчика полный комплект документации.
В реальной жизни такие вещи приходится либо исправлять предварительно (если чертежей много и использование CAT сулит значительные преимущества), либо переводить вручную.
Учитывая тот факт, что самая распространённая CAT — Trados — до 2017 версии не могла объединять сегменты, разбитые абзацами, оптимальным (а иногда единственным) путём решения проблемы является исправление оригинала.
Совет
Если возможность изменения оригинала не заблокирована, объединить необъединяемые сегменты в любой CAT можно вручную простым переносом текста
Некоторые могут возразить: «Ну что за проблема объединить немного разбитых единиц перевода в Trados 2017, DejaVuX или MemoQ?».
Ответ на этот вопрос мы рассмотрим в следующем разделе. (А вдумчивым читателям предлагается додуматься до него самим.)
Сокращения
Касательно сокращений — тут есть несколько решений.
- Настройка списков сокращений в MemoQ, Trados или исключений из правил сегментации в DejaVuX. Поскольку, на мой взгляд, грамотно эта функция реализована только в MemoQ (с автоматическим исправлением сегментации после добавления нового сокращения в список), то грамотный подход к выбору CAT (не просто Trados, чтобы было как у всех) с изучением всех преимуществ и возможностей выглядит предпочтительным решением. Работа с настройкой исключений в DejaVuX требует знания извращённых разновидностей регулярных выражений. Также потребуется повторно импортировать документ с новыми настройками, что приведёт к стиранию уже сделанной части перевода. Он, конечно, будет подставлен обратно из TM1), но только для тех сегментов, которые останутся неизменными. Поэтому более предпочтительным решением (особенно для тех, кто дружит с Views (в DejaVuX и MemoQ)), может быть добавление к имени файла номера версии и импорт его новым файлом в проект.
- Ручное исправление сегментации по мере перевода — простой и эффективный путь, когда сокращений немного.
Мелкие картинки
Что касается картинок, тут проблема опять-таки зависит от используемой CAT: MemoQ не разбивает сегменты на таких картинках, DejaVuX — разбивает, Trados — не помню. Поэтому один из путей решения — использование наиболее адаптированной к собственным потребностям CAT или перевод через неё. Вторым способом, более предпочтительным в преподавании и для технических писателей, является такое построение текста, при котором количество картинок в середине предложений будет минимальным.
Однако следует отметить, что если в некоторых иностранных языках использование имён собственных без пояснительных существительных привычно, в русском это является признаком дурного стиля. Например:
«ХХХ» dichiara … (итал.)
Компания «ХХХ» заявляет …
Поэтому с полями-названиями, кнопками и прочими подстановочными элементами в начале предложения стоит быть осторожнее.
Проблемы вёрстки, снижающие эффективность работы в CAT
Прежде чем говорить о проблемах, мне хотелось определить значение словосочетания «повышение эффективности». Итак, под повышением эффективности работы я подразумеваю следующее:
- уменьшение объёма текста для перевода (насколько это возможно);
- обеспечение последующего эффективного использования сделанных переводов — с максимальным количеством полных совпадений;
- уменьшение количества мусора в тексте и TM → уменьшение размера → повышение скорости работы.
Итак, какие же дефекты оформления мешают нам достичь указанных целей?
- Использование ручных оглавлений, номеров страниц, различных наименований, которые можно заменить полями, ручной нумерации и буллетирования списков и т.п.
- Замусоривание текста — отбивка пробелами абзацных отступов и выключки (выравнивания текста, например, по центру), многочисленные пробелы, использование большого количества шрифтов, буквицы, разнотипных знаков препинания и т.п.
- Табулирование текста вместо использования таблиц.
- Орфографические ошибки.
Оглавление
Как ни печально говорить, но большинство пользователей MS Word/LO Writer не умеют делать автоматическое оглавление. А ведь замена ручного оглавления в документе (при его наличии) на автоматическое перед импортом позволяет сократить объём текста в переводе порой на 10-15%. Кроме того, ручные оглавления часто форматируются так, что даже при полном совпадении с названиями заголовков глав они не дают 100% совпадений по принципам оценки CAT, а нередко, из-за синонимичности, пропусков/добавления артиклей, пробелов и т.д. и т.п. они и не являются полными совпадениями. И представьте, сколько времени может понадобиться на проверку того, а совпадают ли они в переводе. (А потом ещё на проверку непрерывности нумерации нумерованных заголовков, правильности номеров страниц и т.п.)
Вот пример того, как такие горе-оглавления с названиями глав выглядят в MS Word. (Также обратите внимание, насколько криво выглядит текст — разные отступы, пропуски нумерации в тексте, орфографические ошибки.)
| Как было | Как должно быть2) |
|---|---|
 |  |
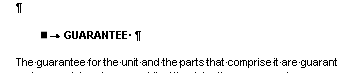 |  |
 |  |
 |
Вот пример автоматического оглавления и двух наиболее часто встречаемых вариантов ручных оглавлений:

И вот как они выглядят в CAT:

Как можно видеть, автоматическое оглавление просто отсутствует в CAT и не требует перевода, сегменты ручного оглавления могут не на 100% совпадать с заголовками в тексте (самые внимательные отметят, вдобавок, отклонение названия
Ещё одним способом уменьшения количества текста в перевод является использование полей и скрытие (или оформление специальным стилем) частей, не требующих перевода — в первую очередь таблиц с многочисленными цифрами и обозначениями. Альтернативой данному решению является настройка CAT на тегирование таких вещей, чтобы они не отображались в таблице перевода.
Замусоренность
Пример замусоренного текста можно легко найти в текстовых документах на сайтах разных вузов. Я же просто покажу самые типичные проблемы на фрагменте текста, распознанного FineReader:

Псевдонумерация, псевдобуллетирование, отбивка пробелами, разный кегль шрифта… Это то, что видно навскидку. То, что не видно навскидку, в CAT может оказаться таким, как показано ниже, бросая в дрожь новичков:

Остряки, конечно, могут сказать: «Ну и в чём тут проблема? Отключить показ непечатных знаков в MS Word — ужас по большей части скроется. Теги зачистить CodeZapper — и всё будет OK». Да, возможно, конкретный документ это спасёт, но в копилку переводов попадёт много замусоренных сегментов, которые с нормальным текстом не дадут даже и 75% совпадения (например, одинаковые заголовки с разными ручными номерами). А это — снижение производительности, порой очень существенное, конкурентоспособности и заработка…
Рассмотрим буллетирование. При автоматическом буллетировании в «Ворд» текст импортируется чистым. С ручным буллетированием, на котором настаивает в своих рекомендациях по подготовке документов к переводу БП «Неотек», не всё так однозначно. Его плюсы и минусы на мой взгляд я привёл ниже:
Плюсы ручного буллетирования
- Большая понятность сути текста при отсутствии оригинала.
Минусы ручного буллетирования
- Больший размер.
- Проблемы с отбивкой:
- отбивка пробелами — в MS Word/LO Writer при выключке по ширине невозможно получить красивый ровный текст;
- отбивка табуляцией — разная обработка табуляции в CAT;
- отбивка неразрывным пробелом. Труднее набирать.
Примерно 50-70% пользователей MS Word/LO Writer не знают, что это такое, и при включении непечатаемых знаков могут начать удалять значок неразрывного пробела, похожий на градус.
- Большое количество разновидностей «буллетов» будет снижать степень совпадения.
- Проблемы с вышеописанными факторами при использовании вручную сопоставленных документов.
Вот так в CAT выглядит буквица:

Совпадение между сегментами с буквицей и без меньше того предела, с которого CAT начинает предлагать совпадения. Т.е., переведя любой из вариантов, вы не увидите его при переходе на другой вариант (в примере хорошо видно, какую проблему представляет синонимичность для ручных оглавлений).
Во-вторых, понимание принципов влияния форматирования и других особенностей оформления текста на степень его совпадения в CAT может дать эффективные способы противодействия тем БП, которые очень любят при своих невысоких расценках дополнительно обирать переводчиков скидками за совпадения.
Табуляции
Рассмотрение влияния табуляции на работу в различных CAT я оставляю читателю для самостоятельной работы. Единственной подсказкой будет то, что Trados и DejaVuX стандартно не разбивают сегменты по табуляции, а MemoQ разбивает.
Проблемы вёрстки, приводящие к искажению внешнего вида готового перевода
Причиной этой проблемы на самом деле является не вёрстка, а отличие длины перевода от длины оригинала — русский перевод, как правило, на 20-30% длиннее английского оригинала.
Итак, какие же подводные камни скрываются здесь…
Во-первых, чем меньше свободные поля на странице, тем больше вероятность того, что добиться постраничного соответствия без уменьшения кегля или подбора специальных уплотнённых шрифтов не удастся (это, как минимум, потребует исправления номеров страниц ручных оглавлений — одна глупость тянет за собой другую).
Во-вторых, при сдвиге текста скорее всего произойдёт его смещение относительно картинок, колонок, позиций табуляции и т.п.
| … | Сдвиг заголовка при увеличении межстрочного интервала и перекрытие его надписью, привязанной к позиции на странице |
|---|---|
 |  |
| … | Порча внешнего вида документа после перевода из-за сдвига текста |
|---|---|
 |  |
Поэтому основное правило при вёрстке под перевод с помощью CAT — минимум позиционно-размерных привязок с отсечением их разрывами страниц. На практике это значит следующее:
- Картинки следует вставлять предпочтительно «в тексте», без обтекания.
- Текст, связанный с картинками, лучше делать в таблицах.
- Рассмотрим пример:

- Можно сделать так (см. отступ):

- И так (рамка таблицы показана специально):

Оформление в таблице будет лучше тем, что даже при изменении длины текста, выставив вертикальное выравнивание в ячейках «посередине», мы всегда получим симметричный параграф, для чего первый вариант, возможно, придётся поправлять вручную после экспорта.
- Надписи следует использовать минимально. Если избежать этого нельзя, после перевода следует внимательно проверить, чтобы текст был виден в надписях полностью (обычно приходится увеличивать размер надписей, уменьшать стандартные поля или уменьшать/заменять шрифт перевода).
Вот пример этой проблемы в документе, некачественно подготовленном для перевода:
- Избегать использования табуляций вместо таблиц. Позиции табуляторов привязываются к странице. В более длинном переводе в некоторых строках произойдёт смещение текста к следующей позиции табуляции, и стройная ровненькая картинка рассыплется. Да, её можно исправить, но это — время, которого гораздо чаще не хватает именно в конце перевода, а не в начале. Кроме того, следует учесть проблемы, связанные с разной обработкой табуляции в разных CAT (и помнить об этом при интенсивном обмене копилками переводов между разными CAT).
- Не использовать форматирование в одну и несколько колонок на одной странице (характерная особенность документов, полученных из FineReader в режиме сохранения с максимальным подобием при непонимании особенностей перевода с помощью CAT).
- Страницы с отклонениями в оформлении от данных указаний по возможности отсекать разрывами до и после.



Желающие изучить вышеописанные проблемы более подробно могут взять какой-нибудь сложный документ, распознать его в FineReader и сохранить с разной степенью подобия (в случае PDF можно воспользоваться каким-нибудь конвертером — Acrobat, Solid и т.п.), после чего загрузить в CAT и, воспользовавшись функцией псевдоперевода длиной 120-130% (перевод на 20-30% длиннее оригинала, что типично для перевода с английского на русский), посмотреть, что получится с внешним видом документа на выходе…
Вот вроде и всё. Возможно, я что-то пропустил и что-то недостаточно осветил. Я не ставил задачу разжевать материал до уровня манной каши. Те, кто называет себя переводчиками, должны сами уметь догрызться до сути в направлениях, которые я хотел показать своим очередным опусом.
P.S. С замечаниями об ошибках, предложениями по улучшению и дополнению просьба обращаться по адресу mikhailo@tut.by
P.P.S. Поскольку разработчики ПО постоянно совершенствуют свои творения, часть информации может уже быть или скоро стать не совсем верной. Однако это не меняет важность рассмотренного вопроса.
За исключением случаев, когда указано иное, содержимое этой вики предоставляется на условиях следующей лицензии: CC Attribution-Noncommercial-Share Alike 3.0 Unported